Varshith Sreeramdass

Varshith Sreeramdass
Robotics PhD Georgia Institute of Technology Atlanta, US Email: vsreeramdass@gatech.edu
Hi! I'm a PhD student at Georgia Institute of Technology, advised by Prof. Matthew Gombolay and Prof. Aaron Young. My research lies in robot learning and human-robot interaction, currently exploring the domains of athletic robots and exoskeletons. I am honoured to be supported by the Robotics PhD fellowship from the Institute of Robotics and Intelligent Machines.
I did my Masters in Computer Science at Georgia Tech, specializing in Computational Perception and Robotics. Before that, I was a Research Engineer at Honda R&D Robotics. My undergraduate studies were at IIT Bombay in Computer Science and Engineering advised by Prof. Sunita Sarawagi and Prof. Soumen Chakrabarti. I also interned at Honda Research Institute Japan.
Links: [CV] [Google Scholar] [Github] [LinkedIn]
Projects and Publications
-
Generalized Behavior Learning from Diverse Demonstrations
Varshith Sreeramdass, Rohan Paleja, Letian Chen, Sanne van Waveren and Matthew Gombolay.
International Conference on Learning Representations 2025 (Poster).
Georgia Institute of Technology, 2025.
[Abstract] [Paper] [Code] [Poster]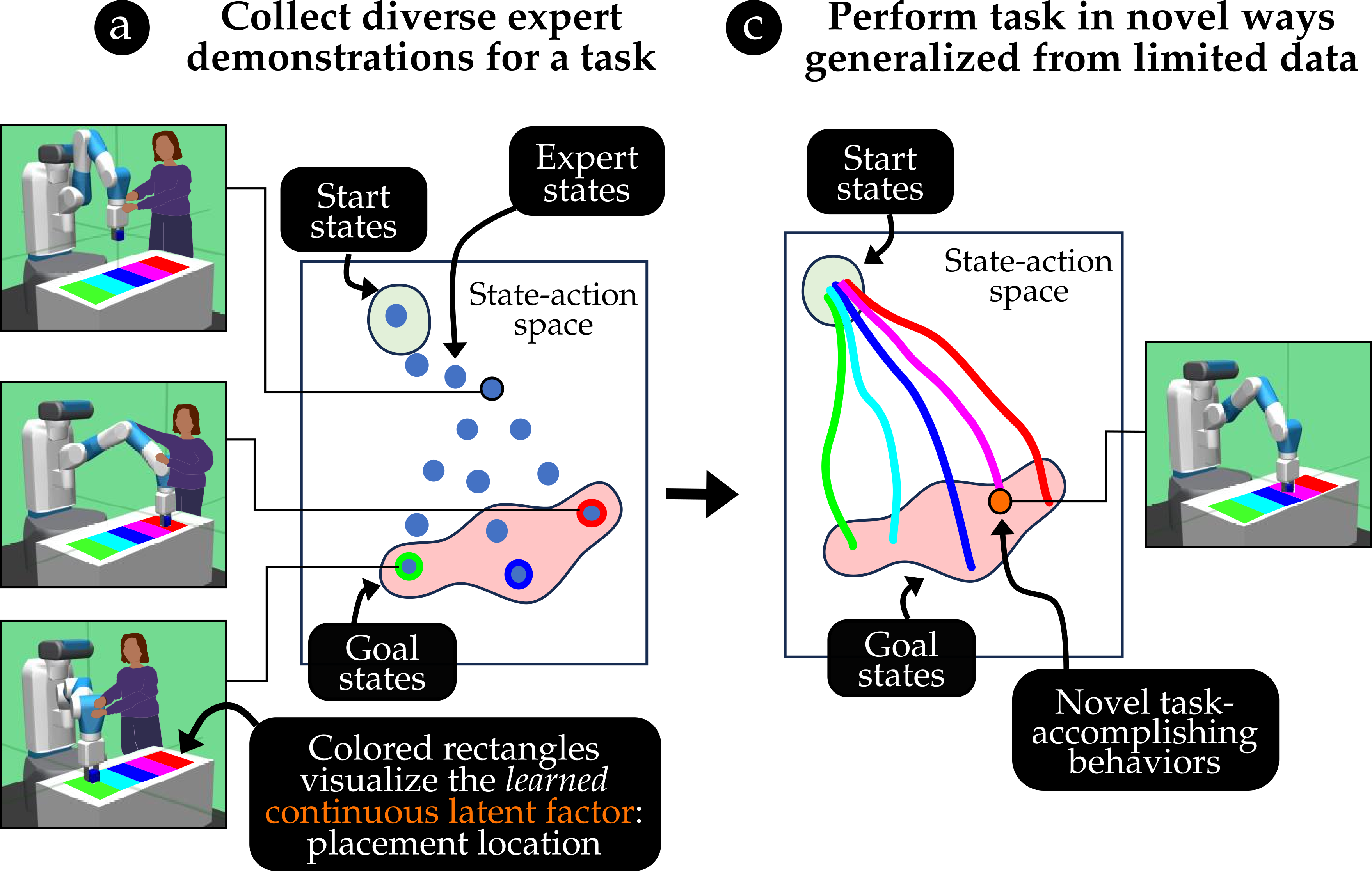
Diverse behavior policies are valuable in domains requiring quick test-time adaptation or personalized human-robot interaction. Human demonstrations provide rich information regarding task objectives and factors that govern individual behavior variations, which can be used to characterize useful diversity and learn diverse performant policies. However, we show that prior work that builds naive representations of demonstration heterogeneity fails in generating successful novel behaviors that generalize over behavior factors. We propose Guided Strategy Discovery (GSD), which introduces a novel diversity formulation based on a learned task-relevance measure that prioritizes behaviors exploring modeled latent factors. We empirically validate across three continuous control benchmarks for generalizing to in-distribution (interpolation) and out-of-distribution (extrapolation) factors that GSD outperforms baselines in novel behavior discovery by ~21%. Finally, we demonstrate that GSD can generalize striking behaviors for table tennis in a virtual testbed while leveraging human demonstrations collected in the real world.
-
Generalized Behavior Learning from Diverse Demonstrations
Varshith Sreeramdass, Rohan Paleja, Letian Chen, Sanne van Waveren and Matthew Gombolay.
First workshop on Out-of-Distribution Generalization in Robotics at CoRL 2023 (Oral).
Georgia Institute of Technology, 2023.
[Abstract] [Paper] [Code] [Poster]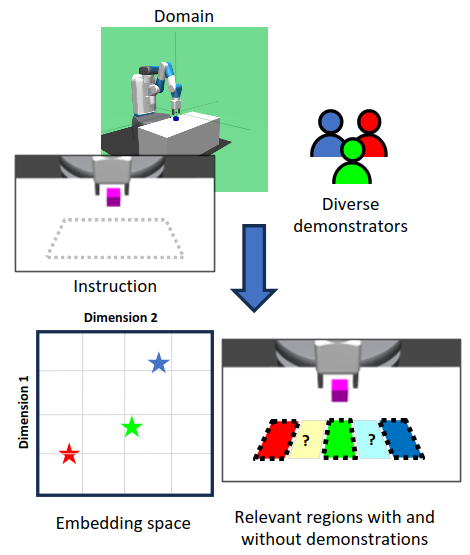
Learning robot control policies through reinforcement learning can be challenging due to the complexity of designing rewards, which often result in unexpected behaviors. Imitation Learning overcomes this issue by using demonstrations to create policies that mimic expert behaviors. However, experts often demonstrate varied approaches to tasks. Capturing this variability is crucial for understanding and adapting to diverse scenarios. Prior methods capture variability by optimizing for behavior diversity alongside imitation. Yet, naive formulations of diversity can result in meaningless representation of latent factors, hindering generalization to novel scenarios. We propose Guided Strategy Discovery (GSD), a novel regularization method that specifically promotes expert-specified, task-relevant diversity. In the recovery of unseen expert behaviors, GSD improves 11% over the next best baseline across three continuous control tasks on average.
-
Structured Policies in Reinforcement Learning for Dexterous Manipulation
Varshith Sreeramdass, Akinobu Hayashi, Tadaaki Hasegawa and Takayuki Osa.
Honda R&D Robotics, 2022.
[Abstract] [Demo, IROS '22]
For real world manipulation through reinforcement learning, exploration presents a significant challenge. Policies with incorporated structure can improve exploration efficiency, making learning feasible. This project explores structure in two forms: (1) parameterized motion primitives as low level policies, and gating policies operating in goal and duration spaces, and (2) residual policies that provide adjustments to actions from scripted base controllers. While simulation results showed that parameterized primitives accelerated learning, performance was limited in scenarios requiring quick, reactive behaviors. In comparison, residual policies showed significant improvements in sample efficiency and robustness to noisy initial conditions. Residual policies transferred through sim-to-real proved robust to an object initialization noise of 3mm in a beverage can-opening task requiring precise contacts and high torques.
-
Data-driven DRL for Dexterous InHand Manipulation
Varshith Sreeramdass, Akinobu Hayashi and Tadaaki Hasegawa.
Honda R&D Robotics, 2021.
[Abstract] [Press Release] [Video]
Learning dexterous manipulation directly on real robots is considerably difficult to do from scratch due to extensive real robot deployment. Sim-to-real is not straight forward due to simulation fidelity. In this work, we employed data-driven reinforcement learning algorithms (DAPG, AWAC) to learn from expert and suboptimal demonstrations. In tasks involving reorientation of objects for tool-use (transitions among precision, tripod and power grasps), we achieved robustness towards noise in object initialization.
-
Domain Adaptation of Cloud NLP Services through Word Substitutions
Varshith Sreeramdass, Vihari Piratla, Sunita Sarawagi and Soumen Chakrabarti.
B. Tech. Thesis (Part II), IIT Bombay, 2019.
[Abstract] [Report] [Survey]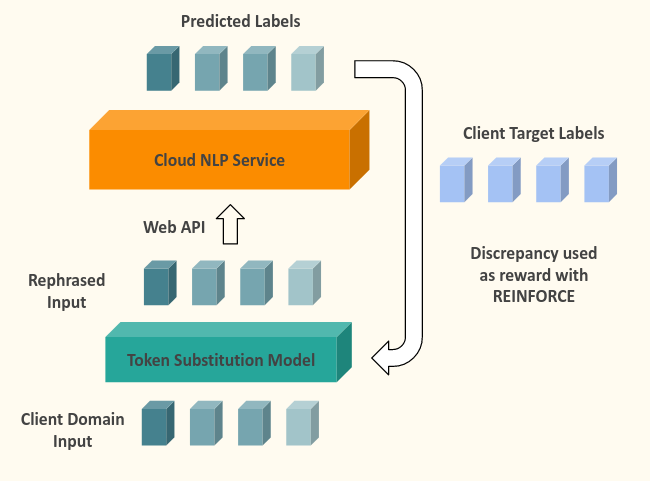
Several cloud services are available which perform natural language tasks like sentiment classification, named entity recognition, dependency parsing, fine type tagging, etc. While these services are trained on a large diverse dataset encompassing a large number of domains, the performance of the service on a specific narrow domain relevant to the application may be sub par. For the tasks of sentiment classification and NER, this work attempts to adapt sentences in the target domain to the domain of the service model, to improve the performance of the service model, through word substitutions.
Additionally, this project also surveyed in depth, methods to learn an optimal active learner using reinforcement learning.
-
Out-of-Distribution Image Detection with Deep Neural Networks
Varshith Sreeramdass and Sunita Sarawagi.
B. Tech. Thesis (Part I), IIT Bombay, 2019.
[Abstract] [Report]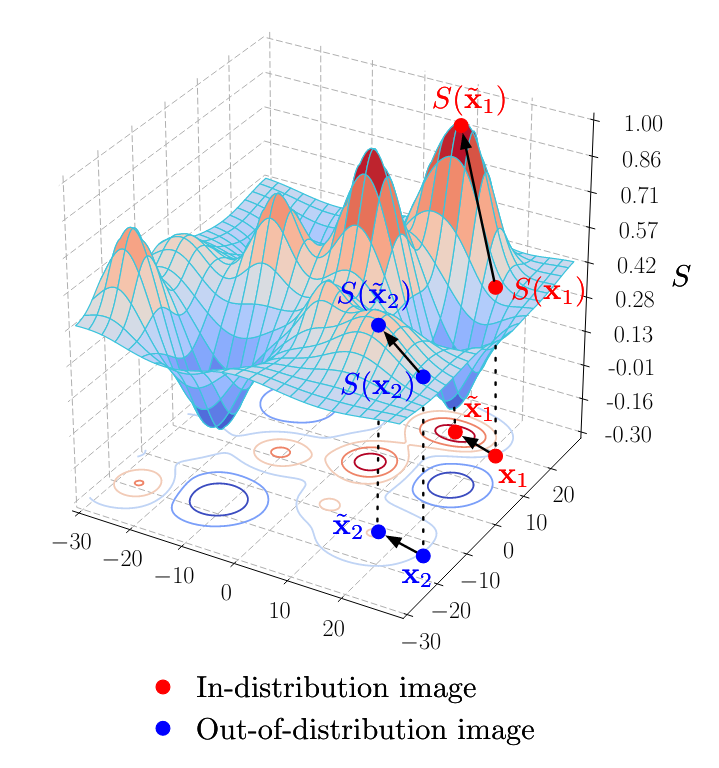
Image: Liang, et. al., 2017
Out-of-distribution detection is vital in the deployment of Deep Neural Networks in practical applications. Several methods exist that range from temperature scaling of logits to model ensembles. This work surveys extensively existing methods for out-of-distribution detection that either use features extracted by pre-trained models, or propose minimal modifications to the framework, analyses their performance, shortcomings and proposes a few simple enhancements that produce comparable results.
-
Augmenting Scene Graph Generation with Knowledge from Corpora
Varshith Sreeramdass, Amrita Saha and Soumen Chakrabarti.
Independent Study Under Faculty, IIT Bombay, Spring 2019.
[Abstract] [Report]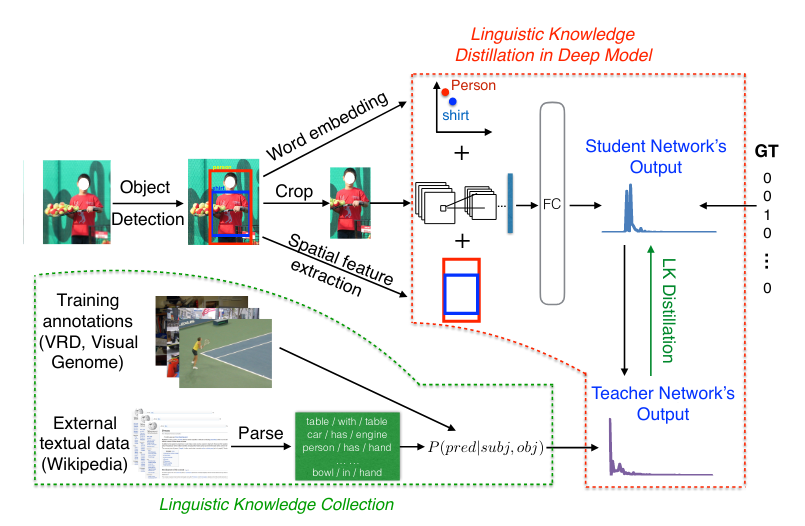
Image: Yu, et al., 2017
Scene graph generation is vital to structuring the information in a visual scene. It is also one of the most challenging tasks in computer vision, requiring an enormous amount of data to learn from. The task can thus benefit from side information, knowledge that is not necessarily in the form of image annotations, but a distribution over the edges of a scene graph obtained from the likes of a relevant knowledge base or a text corpus. This work attempts to study the method of Linguistic Knowledge Distillation (Yu, Ruichi, et al., 2017), and enhance scene graph generation by augmenting with information from various text corpus describing visual scenes, objects and their spatial relationships.
-
Sign Language Synthesis with Styling
Varshith Sreeramdass and Heike Brock.
Internship, HRI-JP, Summer 2018.
[Abstract] [Report] [Code]
To enable communication between those that are ignorant and fluent in sign langauge, seq-to-seq models that generate joint trajectories of virtual characters from sign-language tokens can be leveraged. However, such generated motion tends to feel robotic and lacks natural-human variability. The work attempts to build upon such models to enable variation in style. The model is coupled with style parameters that are learnt in an unsupervised manner using a GAN approach. While the model fails in generating reliable motion usable for communication, the work does explore a representations for motion capture data and invalidate using certain types.
Miscellaneous
- In my free time, I like to try new food, listen to rock music, visit art museums and (occasionally) hike.
- I speak English, Telugu, Hindi and N3 Japanese.
- I borrowed the template for this website from Nelson Liu's homepage.